
Data is expensive. Both in terms of grant funds that pay for equipment and salaries, and in terms of the sheer effort that researchers put into collecting it.
So why, then, is that data stored so lazily? Shoving your hard-earned data into a folder on your desktop and calling it a day is a waste.
In this post, we’ll learn what a relational database is, and we’ll walk through an example question that can be answered in seconds with a relational database, rather than in days with a traditional data storage solution.
How Labs Typically Store Data
Most neuroscience labs do not enforce a standard for data collection and storage.
Instead, graduate students are often left to their own devices, and shove everything in a myriad of files and folders on their desktop.
For highly unstructured data, like video, this isn’t a major issue. But for structured data—data that can be subjected to a common standard and aggregated into a relational database—this is far from ideal.
DEFINITIONS
Unstructured data: Data that cannot be easily fit to a single format.
Structured data: Data that can be easily fit into a single format.
Question
How long would it take to answer this inquiry: “How many neurons has our postdoc, Amy, recorded from?”
Keep this question in mind.
What is a Relational Database?
A relational database is a type of data storage that utilizes tables. A table can simply be thought of as a spreadsheet—with rows and columns.
Here’s an example of a table named neurons:
| id | created_at | mouse_id | median_firing_rate | … |
|---|---|---|---|---|
| 1 | 2024-08-01 08:32:01 | 1049 | 4.81 | … |
| 2 | 2024-08-01 08:32:01 | 1049 | 6.39 | … |
| 3 | 2024-07-12 12:06:52 | 1051 | 1.92 | … |
The id column is the primary key, or index, for the table.
The created_at column indicates when the neuron was added to the table.
The mouse_id is a foreign_key, which means it relates to another table in our database (more on this in a minute).
And the median_firing_rate column (and any additional columns) stores data related to this neuron.
The Magic of Relational Data: Joining Tables
At this point, we could easily shove the neurons table into a Google Sheet and call it a day. But then we would be missing out of the power of relational databases: Joining and querying tables together.
So, let’s add a table called mice:
| id | created_at | collected_by | age | sex | … |
|---|---|---|---|---|---|
| 1049 | 2024-08-01 08:32:01 | 6 | 36w | M | … |
| 1051 | 2024-07-12 12:06:52 | 11 | 39w | F | … |
And a table called investigators:
| id | created_at | name | role | … |
|---|---|---|---|---|
| 6 | 2022-04-29 00:00:00 | Amy | postdoc | … |
| 11 | 2021-08-22 00:00:00 | Mike | graduate_student | … |
Recall our question from above:
Question
How long would it take to answer this inquiry: “How many neurons has our postdoc, Amy, recorded from?”
For the typical neuroscience lab, this could take days to answer.
Let’s say Amy has already left the lab. We will need to track down her computer/server. We will need to learn her file organization (if she had one). We will need to know which mice aren’t appropriate for inclusion in an analysis (hopefully she left notes!)
Now, how long would it take to answer with our relational database?
Well, let’s write a SQL (structured query language) query and find out:
SELECT
COUNT(*)
FROM neurons
JOIN mice ON mice.id = neurons.mouse_id
JOIN investigators ON investigators.id = mice.collected_by
WHERE investigators.name = 'Amy';
If you don’t know SQL, don’t worry.
What is happening here is that we are joining the primary key from one table (e.g., neurons) to the primary key of another (e.g., mice and investigators) and looking for the neurons related to Amy.
This query will return the answer:
2
Amy the postdoc has recorded from 2 neurons (id=1, 2) belonging to 1 mouse (id=1049).
This took me ~20 seconds to write the query, and it would run in milliseconds.
Now, imagine Amy had recorded from 1000s of neurons across dozens of animals. Imagine we had a more complex question, like ‘what is the distribution of neuron firing rate by age?‘
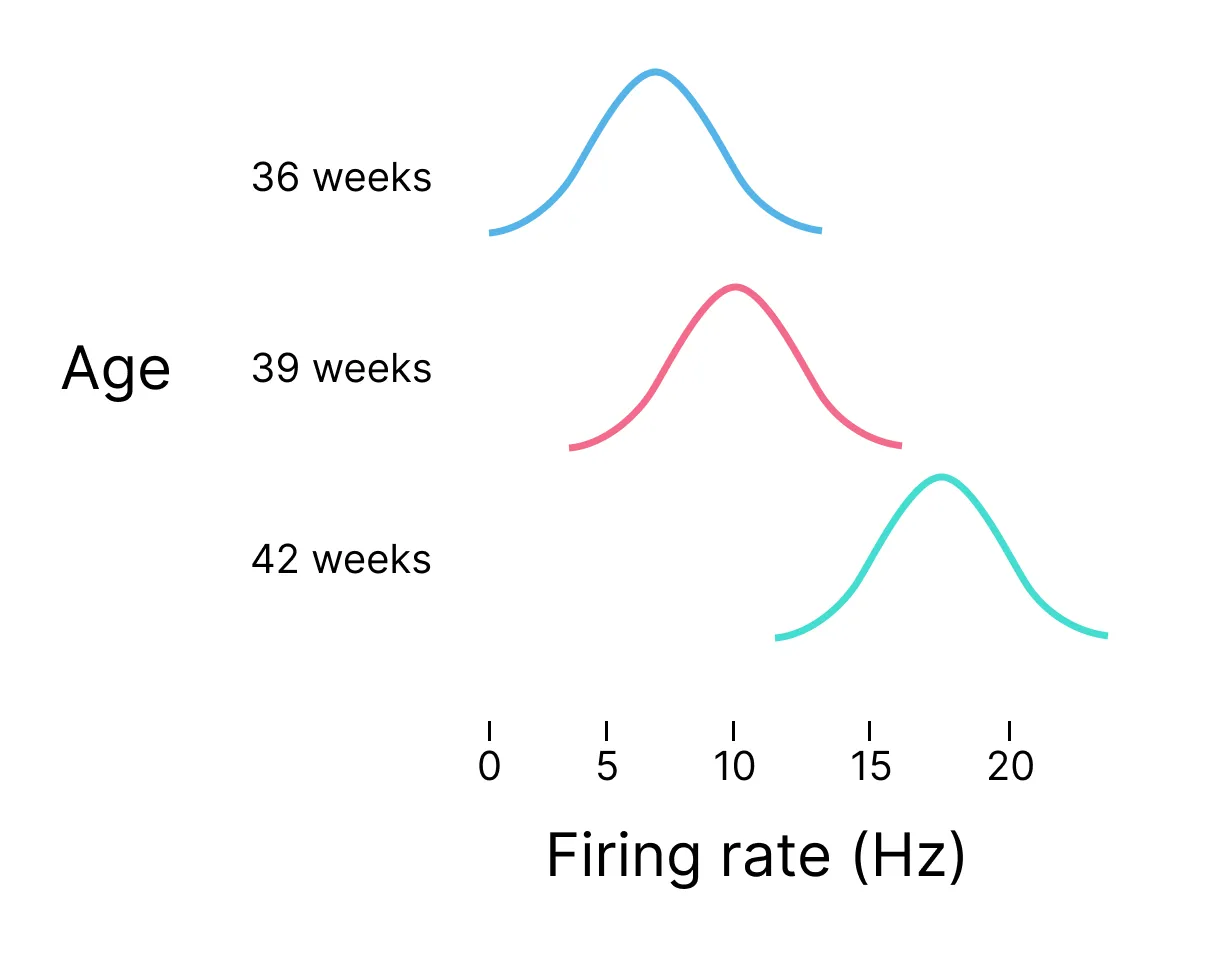
This question could be answered extremely quickly—without sending a research assistant on a week-long mission through every lab member’s idiosyncratic file tree.
What Kind of Data is Stored in A Relational Database?
Structured data, the kind that can be reduced to a mouse’s id (integer), or an investigator’s name (string) or the date the joined the lab (datetime) can be stored in a relational database.
For unstructured data, like video or the raw neural recordings, you will either use a non-relational database, or simply keep them well-organized in your file system.
At the very least, if your students have published data in a paper, that data should be standarized and stored in a relational database.
That way, you always have your lab’s expensive, hard-earned data at your fingertips.
Conclusion
Relational databases consist of tables (in rows and columns, like a Google Sheet). These tables can be joined together for fast, powerful analyses of your lab’s entire corpus of data.
Structured data can be stored in a simple, repeatable format, and is often stored in a relational database.
Unstructured data, such as video, is typically stored in a file system or in some form of non-relational database.
Your lab’s data was expensive to collect—both in terms of funding and effort. You owe it to yourself to store that data in a relational database so that it is always at your fingertips.