GitHub Primer for Neuroscientists
Neuroscientists need to use GitHub. Here's why.
If you want to go fast, go alone; if you want to go far, go together.
In neuroscience, like in many fields, software is at its most powerful when it is shared. More eyes on the code means more bugs are uncovered, more assumptions are shattered, and more features see the light of day.
Moreover, when a lab codes something once (rather than every lab member coding their own version), the lab is more efficient and less likely to have reproducibility issues down the road.
If you share code with your labmates through email, Dropbox, or a flash drive—it’s time to move into the industry standard of version-control systems:
git
What is Git/GitHub/GitLab?
Git is a version-control tool written in C, and it powers two platforms that are commonly used in software engineering: GitHub and GitLab.
WHICH SHOULD I CHOOSE?
Github is far more common in amongst enterprise software companies. Just choose GitHub.
When you store code on GitHub, that’s considered the origin or remote source of the code. It’s the master record for your codebase.
You can pull code from Github onto your own computer, and push it back to Github when you’ve made changes (more on these operations later). That’s your local version of the code.
Why do we use Git?
The best way to understand Git is to compare working with and without Git.
Without git
Imagine you and a labmate are coding together.
Today, you write a script called neuron_statistics.py that takes a neuron’s spike times as its input, and outputs some descriptive statistics like firing rate, inter-spike interval, etc.
v0 looks like this:
import numpy as np
spikes = <neuron_timestamps>
# Calculate firing rate
def calculate_firing_rate(spikes):
n_spikes = len(spikes)
recording_length = spikes[-1] - spikes[0]
firing_rate = n_spikes * recording_length
return firing rate
# Calculate interspike interval
def calculate_isi(spikes):
d_spikes = np.diff(spikes)
isi = np.mean(d_spikes)
return isi
firing_rate = calculate_firing_rate(spikes)
isi = calculate_isi(isi)
print(f"Firing rate: {firing_rate}")
print(f"ISI: {isi}")
So far so good.
That night, you go home and realize there was a bug in the calculate_firing_rate method. It should be n_spikes / recording_length, not n_spikes * recording_length. You make the correction and name your file neuron_statistics_v1.py.
Unbeknownst to you, your labmate went home and decided that the calculate_isi should really calculate the coefficient of variation, as well. They changed the code accordingly:
def calculate_isi(spikes):
d_spikes = np.diff(spikes)
isi = np.mean(d_spikes)
cv = np.std(d_spikes) / isi
return isi, cv
...
isi, cv = calculate_isi(isi)
print(f"Mean ISI: {isi}")
print(f"CV ISI: {cv}")
They too named the file neuron_statistics_v1.py.
Tomorrow, when you come together to work on the project again, you can’t use either of your files! Neither one represents the current state of the script.
Instead, you need to comb through each file, find the differences from the original version, and blend them together.
And that’s exactly what git does for you.
With git
Let’s try this again.
After writing the first version of the script, you both return home and make changes. But instead of saving a new file, you each push your version of the code to GitHub, where the original lives.
Your labmate pushes their changes first. The file now looks like this in GitHub (note the bug in the firing rate calculation is still there):
import numpy as np
spikes = <neuron_timestamps>
# Calculate firing rate
def calculate_firing_rate(spikes):
n_spikes = len(spikes)
recording_length = spikes[-1] - spikes[0]
firing_rate = n_spikes * recording_length
return firing rate
# Calculate interspike interval
def calculate_isi(spikes):
d_spikes = np.diff(spikes)
isi = np.mean(d_spikes)
cv = np.std(d_spikes) / isi
return isi, cv
firing_rate = calculate_firing_rate(spikes)
isi, cv = calculate_isi(isi)
print(f"Firing rate: {firing_rate}")
print(f"Mean ISI: {isi}")
print(f"CV ISI: {cv}")
Now when you go to push your fix, that’s when the magic happens.
You did not pull the most recent changes from GitHub to your computer, because you did not expect your labmate to make changes. So, the file you are trying to push is missing the new ISI functionality.
But that doesn’t matter.
Git knows you are only updating a single line:
firing_rate = n_spikes * recording_length
firing_rate = n_spikes / recording_length
And that line doesn’t conflict with what your labmate wrote. (If there was a direct conflict, git will ask you to resolve it manually.)
The resulting script is now complete in GitHub:
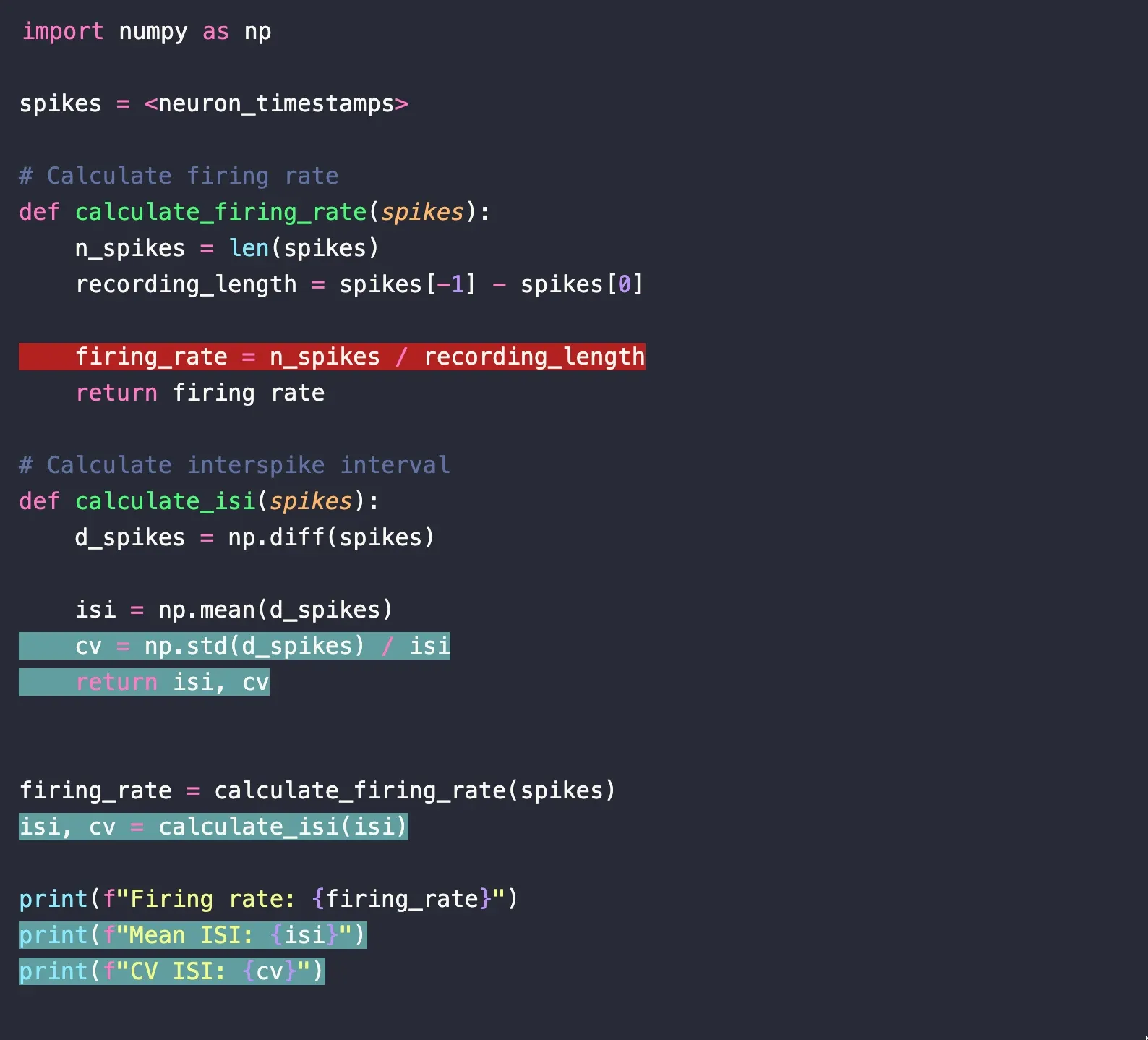
The red-highlighted lines are from you, and the green-highlighted lines are from your labmate.
Git has stitched your work together without the need for manual reconciliation on your part. And even better, git preserves the history of these changes (that’s where version control comes in), so you know exactly what changed, and when.
Now, scale this up to 5, 10, or even 100 people working simultaneously on the same code.
That’s why git is industry standard.
Main features of Git for neuroscientists
Git is a powerful tool, and can get pretty advanced. Fortunately, there are only a few features that are critical to learn off the bat.
Use ChatGPT when you get yourself into a git bind (which will ultimately happen).
Clone
When you clone a repo, you are simply downloading the code to your computer and storing it in a folder.
When you visit a GitHub repo, you’ll see a green button that says ”<> Code”.
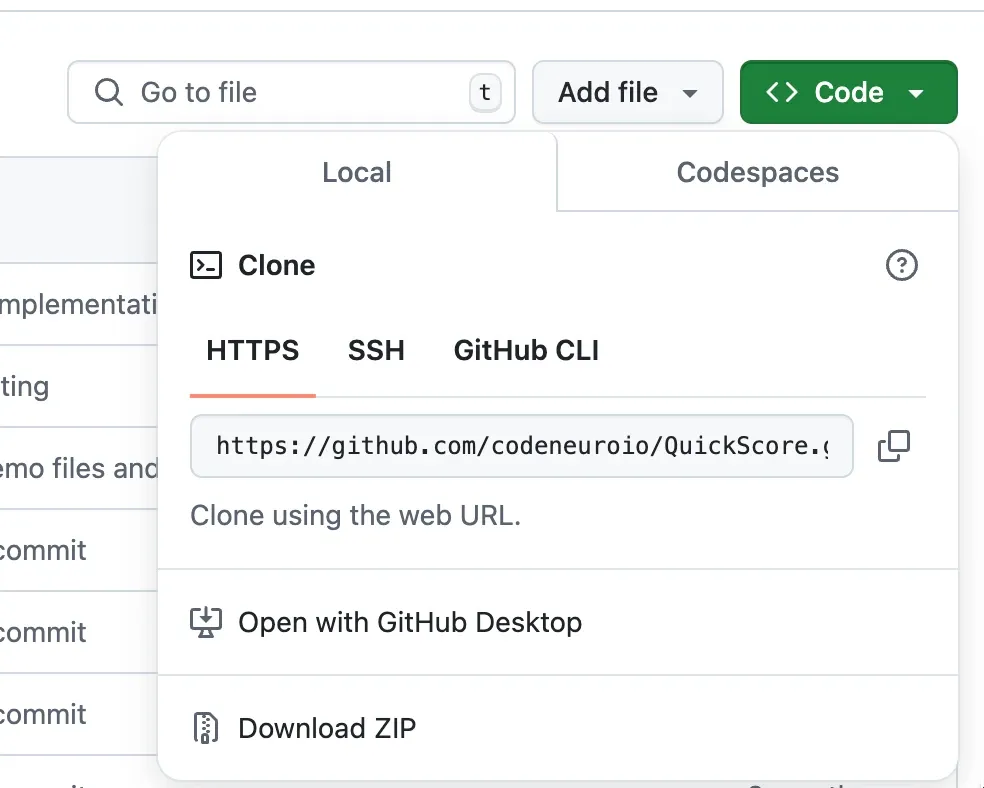
Click this to get the URL of the repo, then run this command in a CLI:
git clone <url>
Now you’ll have a new folder named <repository name> on your computer, in whichever folder your CLI was pointing to.
Pull
Once you have a repository downloaded, you don’t need to clone it again every time. In fact, doing so would overwrite any local changes you made.
Instead, use the following command to grab the up-to-date code from GitHub and weave it into your local version:
git pull origin main
origin refers to the remote/origin server, a.k.a. Github.
main refers to a version of the code—specifically the main version of the code.
(This is typically called master in older repos.)
Add, Commit, Push
These are three separate commands, but you will run them in sequence when you contribute code to the repo.
Pretend you made a small addition to the neuron_statistics.py script:
# Calculate instantaneous firing rate
def calculate_instantaneous_firing_rate(isi):
ifr = 1 / isi
return ifr
For the moment, this change exists only on your computer. You now want to add it to the main branch in GitHub for others to use.
This process is like mailing a letter.
First, you add the changes you made to the envelope:
git add neuron_statistics.py
ADD ALL FILES AT ONCE
If you’ve changed multiple files, you can use this command to add them all at once:
git add .
Second, you write a helpful note on the envelope telling people what’s inside:
git commit -m "adds method to calculate instantaneous firing rate"
The -m flag means “message”.
ADVANCED TOPIC: PRE-COMMIT HOOKS
There is a tool called pre-commit hooks which run some logic before your commit is made. A common flow is to apply formatting and linting to your code before the commit is finalized. Enforcing such a rule keeps your source code consistent across developers.
Third, you send the envelope to its final destination:
git push origin main
(Same syntax as pulling changes, but now you’re pushing them.)
Conclusion
Git, commonly associated with GitHub, is a powerful version-control tool that keeps code up-to-date with many authors.
From a neuroscientist’s perspective, this breaks down into the official code (origin/remote, stored on GitHub) and a local version (on your own computer).
You use the clone and pull commands to get code from GitHub to you, and the add, commit, and push commands to send your code to GitHub.
Using git will prevent your lab from wasting time writing code more than once, manually curating code from multiple authors, and could potentially save you from replication issues down the line.